一个文件含有5亿行,每行是一个随机整数,需要对该文件所有整数排序。
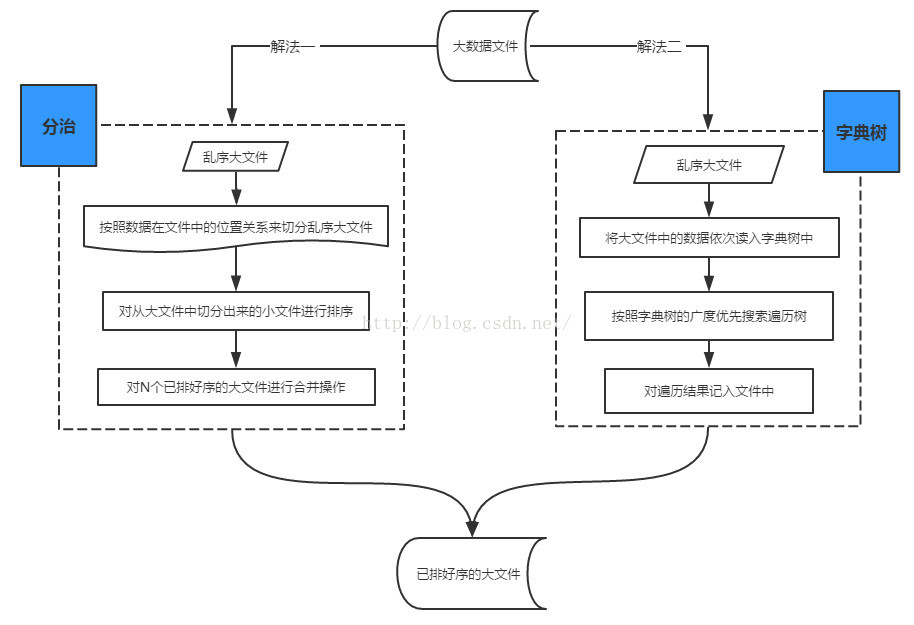
解法一、分治(Divide&Conquer)
对这个一个500000000行的 total.txt 进行排序,该文件大小 4.6G。
每读10000行就排序并写入到一个新的子文件里(这里使用的是快速排序)。
1.分割 & 排序
#!/usr/bin/python2.7
import time
def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def quick_sort(lst):
if len(lst) < 2:
return lst
pivot = lst[0]
left = [ ele for ele in lst[1:] if ele < pivot ]
right = [ ele for ele in lst[1:] if ele >= pivot ]
return quick_sort(left) + [pivot,] + quick_sort(right)
def split_bfile(bfile):
count = 0
nums = []
for line in readline_by_yield(bfile):
num = int(line)
if num not in nums:
nums.append(num)
if 10000 == len(nums):
nums = quick_sort(nums)
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write('\n'.join([ str(i) for i in nums ]))
nums[:] = []
count += 1
print count
now = time.time()
split_bfile('total.txt')
run_t = time.time()-now
print 'Runtime : {}'.format(run_t)会生成 50000 个小文件,每个小文件大小约在 96K左右。
程序在执行过程中,内存占用一直处在 5424kB 左右
整个文件分割完耗时 94146 秒。
2.合并
#!/usr/bin/python2.7
# -*- coding: utf-8 -*-
import os
import time
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行,即当前文件最小值
nums = []
tmp_nums = []
for fd in fds:
num = int(fd.readline())
tmp_nums.append(num)
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
count = 0
while 1:
val = min(tmp_nums)
nums.append(val)
idx = tmp_nums.index(val)
next = fds[idx].readline()
# 文件读完了
if not next:
del fds[idx]
del tmp_nums[idx]
else:
tmp_nums[idx] = int(next)
# 暂存区保存1000个数,一次性写入硬盘,然后清空继续读。
if 1000 == len(nums):
with open('final_sorted.txt','a') as wf:
wf.write('\n'.join([ str(i) for i in nums ]) + '\n')
nums[:] = []
if 499999999 == count:
break
count += 1
with open('runtime.txt','w') as wf:
wf.write('Runtime : {}'.format(time.time()-now))程序在执行过程中,内存占用一直处在 240M左右
跑了3x个小时左右,才合并完不到5千万行数据…
虽然降低了内存使用,但时间复杂度太高了;可以通过减少文件数(每个小文件存储行数增加)来进一步降低内存使用。